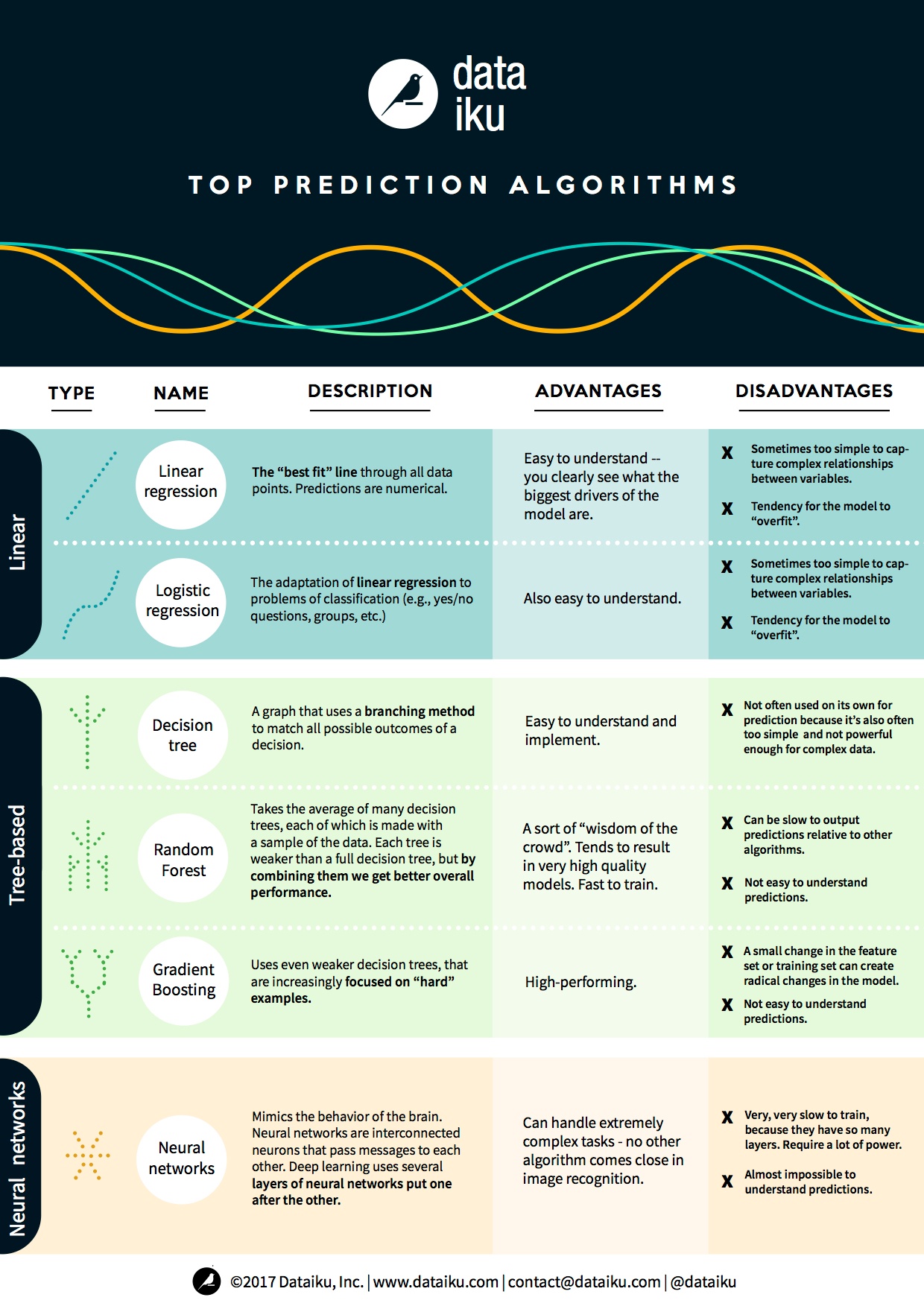
By Nermin Hajdarbegovic, Technical Editor at Toptal
At a glance, the hosting industry may not appear exciting, but it's grunts in data centres the world over that keep our industry going. They are, quite literally, the backbone of the Internet, and as such they make everything possible: from e-commerce sites, to smart mobile apps for our latest toys. The heavy lifting is done in boring data centres, not on our flashy smartphones and wafer thin notebooks.
Whether you’re creating a virtual storefront, deploying an app, or simply doing some third-party testing and development, chances are you need some server muscle. The good news is that there is a lot to choose from. The hosting industry may not be loud or exciting, but it never sleeps; it’s a dog eat dog world, with cutthroat pricing, a lot of innovation behind the scenes, and cyclical hardware updates. Cloud, IaaS and PaaS have changed the way many developers and businesses operate, and these are relatively recent innovations.
In this post I will look at some hosting basics from the perspective of a freelance developer: what to choose and what to stay away from. Why did I underline freelance software engineers? Well, because many need their own dev environment, while at the same time working with various clients. Unfortunately, this also means that they usually have no say when it comes to deployment. For example, it’s the client’s decision how and where a particular web app will be hosted, and a freelancer hired on short-term basis usually has no say in the decision. This is a management issue, so I will not address it in this post other than to say that even freelancers need to be aware of options out there. Their hands may be tied, but in some cases clients will ask for their input and software engineers should help them make an informed decision. Earlier this week, we covered one way of blurring the line between development and operations: DevOps. In case you missed that post, I urge you to check it out and see why DevOps integration can have an impact on hosting as well.
Luckily, the hosting industry tries to cater to dev demand, so many of hosting companies offer plans tailored for developers. But wait, aren’t all webhosting plans just as good for developers as these “developer” plans? Is this just clever marketing and a cheap SEO trick?
Filtering Out the Noise
So, how does one go about finding the right hosting plan? Google is the obvious place to start, so I tried searching for “hosting for developers.” By now, you can probably see where I am going with this. That particular search yielded 85 million results and enough ads to make Google shareholders pop open a bottle of champagne.
![]()
If you’re a software engineer looking for good hosting, it’s not a good idea to google for answers. Here’s why.
There is a very good reason for this, and I reached out to some hosting specialists to get a better idea of what goes on behind the scenes.
Adam Wood, Web Hosting Expert and Author of Ultimate Guide to Web Hosting explained:
“Stay away from Googling ‘hosting for developers.’ That shows you hosts that have spent a lot of money on SEO, not a lot of energy on building an excellent platform.”
Wood confirmed what most of us knew already: A lot of “hosting for developers” plans are marketing gimmicks. However, he stressed that they often offer perfectly fine hosting plans in their own right.
“The ‘hosting’ is real, the ‘for developers’ part is just marketing,” he added.
Although Wood works for hosting review site WhoIsHostingThis, he believes developers searching for a new host should rely on more than online searches.
Instead of resorting to Google, your best bet for finding the perfect plan for your dev needs is word of mouth and old-fashioned research:
- Check out major tech blogs from developers using the same stack as you.
- Reach out to the community and ask for advice.
- Take a closer look at hosting plans offered by your current host. Look for rapid deployment tools, integration to other developer tools, testing support and so on.
- Make sure you have clear needs and priorities; there’s no room for ambiguity.
- Base your decision on up-to-date information.
Small Hosts May Have Trouble Keeping Up
But what about the hundreds of thousands of hosting plans tailored for developers? Well, they’re really not special and in most cases you can get a similar level of service and support on a “plain Jane” hosting plan.
Is there even a need for these small and inexpensive plans? Yes, there is. Although seasoned veterans probably won’t use them, they are still a piece of the puzzle, allowing small developers, hobbyists and students to hone their skills on cheap, using shared hosting plans that cost less than a gym membership. Nobody is going to host a few local hobby sites on AWS, and kids designing their first WordPress sites won’t get a VPS. In most cases, they will use the cheapest option out there.
Cheap, shared hosting plans are the bread and butter of many hosting outfits, so you can get one from an industry leader, or a tiny, regional host. The trouble with small hosts is that most of them rely on conventional reseller hosting or re-packaging cloud hosting from AWS and other cloud giants. These plans are then marketed as shared hosting plans, VPS plans, or reseller plans.
Bottom line: If something goes wrong with your small reseller plan, who are you going to call in the middle of the night?
Small hosts are fading and this is more or less an irreversible trend. Data centres are insanely capital-intensive; they’re the Internet equivalent of power stations, they keep getting bigger and more efficient, while at the same time competing to offer lower pricing and superior service. This obviously involves a lot of investment, from huge facilities with excellent on-site security and support through air-conditioning, redundant power supply and amazingly expensive Internet infrastructure. On top of that, hosts need a steady stream of cutting edge hardware. Flagship Xeons and SAS SSDs don’t come cheap.
There is simply no room for small players in the data centre game.
Small resellers still have a role to play, usually by offering niche services or a localisation, including local support in various languages not supported by the big host. However, most of these niches and potential advantages don’t mean a whole lot for the average developer.
The PaaS Revolution
Less than a decade ago, the industry revolved around dedicated and shared hosting, and I don’t think I need explain what they are and how they work.
Cloud services entered the fray a few years ago, offering unprecedented reliability and scalability. The latest industry trends offer a number of exciting possibilities for developers in the form of developer-centric Platform-as-a-Service (PaaS) offerings.
![]()
PaaS is the new black for many developers. How does it compare to traditional hosting?
Most developers are already familiar with big PaaS services like Heroku, Pantheon and OpenShift. Many of these providers began life as platforms for a specific framework or application. For example, Heroku was a Ruby-on-Rails host, while Pantheon was a Drupal managed-hosting provider, which expanded to WordPress.
PaaS services can be viewed as the next logical step in the evolution of managed hosting. However, unlike managed hosting, PaaS is geared almost exclusively toward developers. This means PaaS services are tailored to meet the needs of individual developers and teams. It’s not simply about hosting; PaaS is all about integrating into a team’s preferred workflow by incorporating a number of features designed to boost productivity. PaaS providers usually offer a host of useful features:
· Ability to work with other developer tools like GitHub.
· Supports Continuous Integration (CI) tools like Drone.io, Jenkins, and Travis CI.
· Allows the creation of multiple, clonable environments for development, testing, beta, and production.
· Supports various automated testing suites.
Best of all, many PaaS providers offer free developer accounts. Heroku and Pantheon both allow developers to sample the platform, thus encouraging them to use it for projects later on. In addition, if one of these experimental projects takes off, developers are likely to remain on the platform.
It’s clever marketing, and it’s also an offer a lot of developers can’t afford to ignore. PaaS is here to stay and if you haven’t taken the plunge yet, perhaps it is time to do a little research and see what’s out there.
Traditional Hosting And Cloud Offerings
Dedicated and shared hosting aren’t going anywhere. They were the mainstays of web hosting for two decades and they’re still going strong. A lot of businesses rely on dedicated servers or VPS servers for their everyday operations. Some businesses choose to use cloud or PaaS for specific tasks, alongside their existing server infrastructure.
In some situations, PaaS can prove prohibitively expensive, but powerful dedicated servers don’t come cheap, either. The good news is that PaaS can give you a good idea of the sort of resources you will need before you decide to move to a dedicated server. Further, PaaS services tend to offer better support than managed VPS servers or dedicated servers.
Of course, all this is subjective and depends on your requirements and budget.
![]()
PaaS, dedicated servers, VPS plans, or your own slice of the Cloud. What should a freelance software engineer choose?
Call me old-fashioned, but I still believe dedicated servers are the best way of hosting most stuff. However, this only applies to mature projects; development is a whole other ball game. Managed dedicated servers offer exceptional reliability and good levels of support, along with good value for money.
Properly used, dedicated servers and PaaS can speed up deployment as well, as Adam Wood explains:
“I can spin up a new Ruby-on-Rails app on Heroku in a matter of minutes. Doing the same thing on AWS takes me a half a day, and I constantly feel like I’m about to break something.”
Cloud services are inherently more efficient than dedicated hardware because you only use the resources you need at any given time. For example, if you are operating a service that gets most of its traffic during office hours (from users in the Americas), your dedicated server will be underutilised for 12 to 16 hours. Despite this obvious efficiency gap, dedicated servers can still end up cheaper than cloud solutions. In addition, customers can customise and upgrade them the way they see fit.
Cloud is catching up, but dedicated servers will still be around for years to come. They’re obviously not a good solution for individual developers, but are for a lot of businesses. VPS plans cost a lot less than dedicated servers and are easily within the reach of individual developers, even though they don’t offer the same level of freedom as dedicated servers.
What Does This Mean For Freelancers?
The good news is that most freelance software engineers don’t need to worry about every hosting option out there. While it’s true that different clients have different ways of doing things, in most cases it’s the client’s problem rather than yours.
This does not mean that different hosting choices have no implications on freelancers; they do, but they are limited. It is always a good idea to familiarise yourself with the infrastructure before getting on board a project, but there is not much to worry about. Most new hosting services were developed to make developers’ lives easier and keep them focused on their side of the project. One of the positive side-effects on PaaS and cloud adoption is increasing standardisation; most stacks are mature and enjoy wide adoption, so there’s not a lot that can go wrong.
Besides, you can’t do anything about the client’s choice of infrastructure, for better or for worse. But what about your own server environment?
There is no one-size-fits-all solution; it all depends on your requirements, your stack, and your budget. PaaS services are gaining popularity, but they might not be a great solution for developers on a tight budget, or those who don’t need a hosting environment every day. For many freelancers and small, independent developers, VPS is still the way to go. Depending on what you do, an entry-level managed dedicated server is an option, and if you do small turnkey web projects, you may even consider some reseller packages.
The fact that big hosting companies continue to compete for developers’ business is, ultimately, a good thing. It means they’re forced to roll out timely updates and offer better support across all hosting packages in order to remain competitive. They are not really competing with PaaS and cloud services, but they still want a slice of the pie.
Remember how PaaS providers offer developers various incentives to get on board, just so they could get their business in the long run? It could be argued that conventional hosting companies are trying to do the same by luring novice developers to their platform, hoping that they will be loyal customers and use their servers to host a couple of dozen projects a few years down the road.
The Future Of Hosting
Although the hosting industry may not appear as vibrant and innovative as other tech sectors, this is not entirely fair. Of course, it will always look bland and unexciting compared to some fast-paced sectors, but we’re talking about infrastructure, not some sort of get rich quick scheme.
The hosting industry is changing, and it is innovative. It just takes a bit longer to deploy new technology, that’s all. For example, a logistics company probably changes its company smartphones every year or two, but its delivery vehicles aren’t updated nearly as often, yet they’re the backbone of the business.
Let’s take a quick look at some hosting industry trends that are becoming relevant from a software development perspective:
· Continual development and growth of Cloud and PaaS services.
· Evolution of managed hosting into quasi-PaaS services.
· Increasing integration with industry standard tools.
· New hardware might make dedicated servers cheaper.
Cloud and PaaS services will continue to mature and grow. More importantly, as competition heats up, prices should come down. The possibility of integrating various development tools and features into affordable hosting plans will continue to make them attractive from a financial perspective. Moving up on the price scale, managed hosting could also evolve to encompass some features and services offered by PaaS. If you’re interested in hosting industry trends, I suggest you check out this Forbes compilation of cloud market forecasts for 2015 and beyond.
Dedicated servers will never be cheap, at least not compared to shared and VPS plans. However, they are getting cheaper, and they could get a boost in the form of frugal and inexpensive ARM hardware. ARM-based processors tend to offer superior efficiency compared to x86 processors, yet they are relatively cheap to develop and deploy. Some flagship smartphones ship with quad-core chips, based on 64-bit Cortex-A57 CPU cores, and the same cores are coming to ARM-based server processors.
As a chip geek, I could go on, but we intend to take an in-depth look at the emerging field of ARM servers in one of our upcoming blog posts, so if you’re interested, stay tuned.
This article originally appeared in Toptal link at https://www.toptal.com/it/hosting-for-freelance-developers-paas
To try out Morpheus' leading PaaS offering sign up for a free demo here.