No industry hypes like the tech industry. The Internet of Things, Big Data, AI, Cloud, DevOps… All are world-changing, trillion-dollar opportunities that your company can't afford to miss out on, according to the pundits and vendors alike.
Well, maybe it's time to take a tip from those famous technology naysayers, the Amish. That's the suggestion of Michael J. Coren in a May 18, 2018, long read on Quartz. A common misconception is that the Amish see technology as inherently evil. As Coren points out, there are no rules in the religious community that prohibit the use of new inventions.
What the Amish possess is a strong understanding of, and unshakable confidence in their way of life: For them, there is no greater calling than to be a farmer. Coren highlights the deliberate approach the Amish take to new technology. "They watch what happens when we adopt new technology," according to Wetmore, "and then they decide whether that's something they want to adopt for themselves."
Know your people and don’t underestimate tool impact
Now, we’re not suggesting to turn your back on a fully automated multi-cloud deployment toolchain. However, the lesson organizations can learn from the incredibly selective stance the Amish take toward innovation is to know who you are, stay focused on your goals, and to always be true to your community. The decision to adopt a new technology depends on whether it's a good fit for your culture and a boon to your company's long-term success.

While 73 percent of the companies participating in IDC's 2017 Cloudview survey claim to have a hybrid cloud strategy, 61 percent claim they lack IT staff skilled in the use of cloud automation tools. Source: IDC, via Digitalist
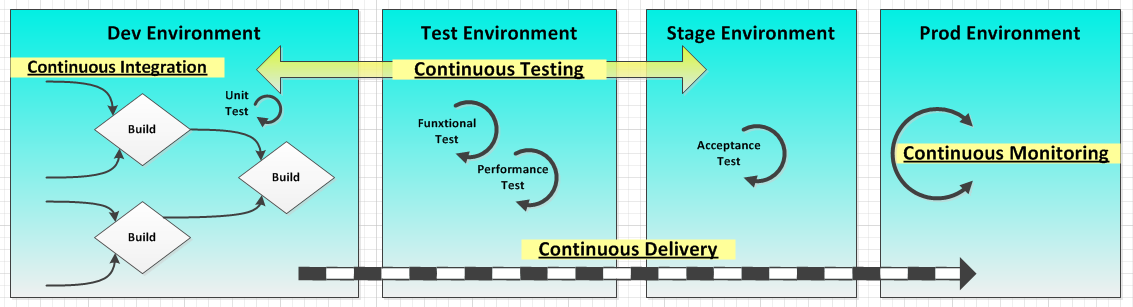
It seems obvious that companies would begin their planning for DevOps by shopping for tools. After all, vendors announce shiny new-and-improved offerings almost daily. But you can't expect to realize tangible benefits until your management framework runs at cloud speed, stakeholders have bought in, and IT workers acquire the right skills.
As development cycles become shorter, teams have to innovate faster to keep pace. This translates into near-constant collaboration, on-demand resource allocation, and the "redistribution of accountability" within and outside of IT. The required level of management integration isn't possible without unprecedented visibility into how, where, and when software is being used.
Understanding the link between tools and process
It's not uncommon for companies to be dazzled by the breadth and depth of the hybrid cloud management tools now available. They may feel the need to adopt the latest-greatest favorites of the tech media hype machine rather than select only those tools that meet their hybrid-cloud management needs. In a recent TechBeacon article, David Linthicum includes "understanding the tools" as one of the five essentials for managing hybrid clouds.
Linthicum recommends that organizations "start with the essentials": Understand your unique needs in terms of security, data, governance, and end-user dynamics. Step one is listing what exactly is being managed. Profile the workloads that will run on public and private clouds but as importantly address the teams and processes that surround the workload. Among the questions to answer are who "owns" the workloads, who needs to be alerted when problems arise, and how critical specific workloads are to the organization.
Linthicum also emphasizes the need for a single pane of glass to address the complexity of hybrid cloud management. Learning and accommodating all the native APIs and resources used by cloud providers is impractical in terms of cost and efficiency. The best solution is something like Morpheus, which abstracts the hybrid-cloud interface to a layer that lets you decide which hybrid-cloud components are most important for your operation.
IT focus shifts to the 'employee experience'
For many veteran IT managers, hardware and software is their comfort zone. In the cloud era, most of the work done by the IT department exists outside the data center and instead takes place wherever the organization's employees operate. This has led many companies to extend their "customer experience" efforts to internal staff and service delivery processes.
That's the goal Adobe CIO Cynthia Stoddard set for her department via a program entitled "advancing the inside." CMO's Nadia Cameron writes that Adobe's goal is to improve the employee experience just as much as the company works to enhance its customers' experiences.

The digital era requires that leaders adopt new ways of thinking, acting, and reacting, particularly when meeting the workplace needs of their employees. Source: Deloitte University Press, via Edublogs
Rather than attempt to "shut down" shadow IT in the company, Stoddard embraces it as a way for employees to "control their destiny." The goal is to create security "guardrails" that employees must operate within, and any technology that operates inside those guardrails is sanctioned. A result of Adobe's employee-experience emphasis has been workers from business units spending more time "inside IT". The silos that once predominated in enterprises are not being blown up so much as they're being transformed into conduits that connect every part of the organization.
At Morpheus, we’ve often been pulled into the stormy sea of organizational dysfunction as part of major cloud management and DevOps automation projects. One major lesson learned is that each major stakeholder group must get their base level needs met in order for higher-level communication to be successful.
As an example, Infrastructure and Ops teams need to feel they are meeting the service level and security needs of the business. Developers need to see rapid deployment times so their code pushes to production quickly. Management teams are looking for consolidated reporting, cost controls, and return on investment. If you can meet all three of these needs from a single tool then you may be on the right track.
To learn about how Morpheus could help these three groups all feel like they’re winning please setup time for a demo with one of our solution architects.
_original.png)